| Previous Post | Top | Next Post |
TOC
Unidicの頻度情報は日本人名をカタカナ登録で処理している。
かな漢字変換のデーターを作るのにはこれではまずいので別情報で漢字補完すべきです。 さてどうするべきか?
姓名
2019-05-07:内容追加
日本人姓名をカタカナ表記化で集約統計するのは頻度情報集計時の追加後処理 操作のようです。
mecab処理に使うunidicの元ファイルの辞書lex.csvには漢字も収録されていました。
たとえば、「ヒロシ」だと:
ひろし,14726,15499,7326,名詞,固有名詞,人名,名,...
ヒロシ,14726,15499,1100,名詞,固有名詞,人名,名,...
博,14726,15499,5515,名詞,固有名詞,人名,名,...
博史,14726,15499,6555,名詞,固有名詞,人名,名,...
博司,14726,15499,6556,名詞,固有名詞,人名,名,...
博士,14726,15499,8204,名詞,固有名詞,人名,名,...
博師,14726,15499,6556,名詞,固有名詞,人名,名,...
博志,14726,15499,6556,名詞,固有名詞,人名,名,...
博至,14726,15499,6556,名詞,固有名詞,人名,名,...
博詞,14726,15499,6556,名詞,固有名詞,人名,名,...
博資,14726,15499,6556,名詞,固有名詞,人名,名,...
啓,14726,15499,7246,名詞,固有名詞,人名,名,...
啓史,14726,15499,6556,名詞,固有名詞,人名,名,...
...
数えると「名詞,固有名詞,人名,名」で読みが「ヒロシ」が86ありました。 他の名前情報源の列挙数と比較して遜色なくこれだけで十分な感じです。
ちなみに、lex.csvの最初の4つは必須エントリの意味は
- 表層形
- 左文脈ID (単語を左から見たときの文脈 ID)
- 右文脈ID (単語を右から見たときの文脈 ID)
- 単語コスト (小さいほど出現しやすい)
となっています。
こうなると、4つ目のエントリが最小の1100の「ヒロシ」が代表とも言えるし、 漢字で選ぶなら「博」を第一番目漢字変換候補とするなどで簡単に候補序列の 設定にも対応できそうです。
難しそうだった名前でこれですから、姓の方はもっと簡単ですね。
以下の記事の姓名の頻度感は面白いので、ここにほぼ元の形で残し、改訂します
ちなみに、頻度関連情報ですが、頻度順位(rank)には「#」を数字の前につけ表記し、 発生頻度はpmw(1000,000語あたりの発生数)で表記しています。
名字
名字は地名と重なることが多いので、その漢字から漢字設定をし、 品詞を固有名詞(地名・名字可)とでもしていけば、多くは漢字の補完が 来きる可能性がある。特に全国郵便番号の地名(漢字+カナ)は網羅的で有効。 沖縄の変わった名前なども、意外と地名にあります。
名字の参考情報
全国名字ランキング による情報にrank pmwを合わせて比較 (40000位まである公開順位情報の一部のFAIR引用)
RANK PMW cost
1位 佐藤 およそ1,880,000人 #2773 30 4251
2位 鈴木 およそ1,802,000人 #2855 29 2538
4位 田中 およそ1,340,000人 #2289 38 2734
10位 加藤 およそ890,000人 #3916 19 5087
20位 清水 およそ533,000人 #5854 11 2814
40位 坂本 およそ327,000人 #6348 10 4586
100位 杉本 およそ182,000人 #13375 3.4 6101
200位 南 およそ106,000人 #17521 2.3 7703
400位 高瀬 およそ51,200人 #33790 0.76 7279
1000位 岩村 およそ18,300人 #31653 0.86 6108
2000位 嵯峨 およそ7,700人 #22960 1.5 7431
3994位 蓑輪 およそ3,000人 #76505 0.12 6108
10000位 ........1000人を切る 出てこない
これ以下だと読めない名前多し
ちなみに珍しいが
歴史的なアイシンカクラは #134146 0.019 6108
0.1 pmw以下(4000位以下)は特殊な名前とも言えるが、それ以上の頻度(少なくとも上位2000位まで) はかな漢字変換をしたい。
2019-05-09追加: mecabのcostとpmwの相関をざっくり見てみた
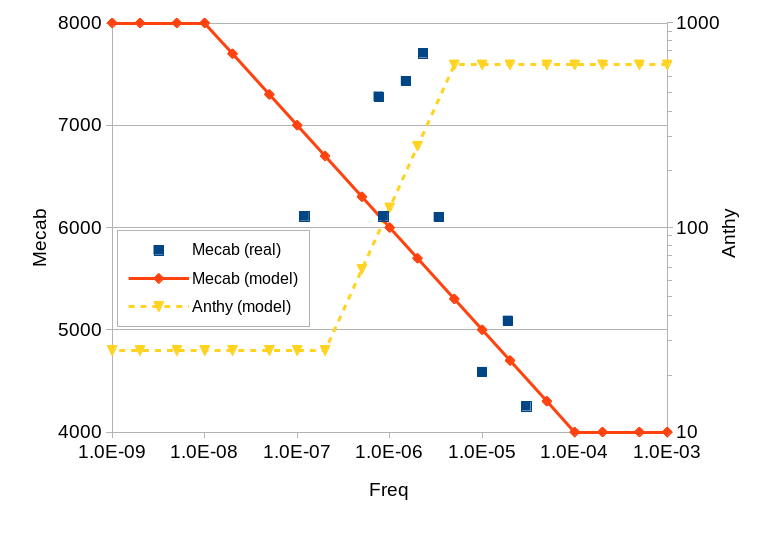
完全では無いが、ある程度の相関は有りそうでした。これにあわせて、 単語発生頻度pmwから、mecabのcostや、anthyのfreqを概算推定する モデルも作りました。anthyのfreqはもと辞書中記載の数字で、プログラム 内では8倍して使われています。ちょうど1 pmwが125なので、8倍されると 内部で1000になっています。
名前
ここは、まずBCCWJ_frequencylist_luw_ver1_1.tsvの利用を考えたい。 カタカナ化する前の漢字のデーターを残して集計し、頻度も計算している。 短単位語彙表で名前の音を洗い出し漢字を長単位語彙表からとるのが ライセンスも同じなので一番きれい。50以上の漢字候補が見つかれば最低限十分かな? かな?ただ、名前部分の抽出はかなり手間がかかりそう。
さらに他ソースから参考情報を補う。Anthy/cannadicはGPL JumannはApache License, Version 2.0ライセンス。anthyだと82の候補有り。SJ3等も含めて 調べるか? mecab-ipadic-neologd や mecab-unidic-neologd これから抽出・逆引きするのもあるかもしれない。‘Apache License, Version 2.0’. 参照
いずれを使おうと、ライセンスコンタミを考え慎重に作業する必要有り。 参照
固有名詞(地名)辞書補強: KEN_ALL.ZIP (郵便番号データファイル)
処理手続き案
- 元データーKEN_ALL.ZIPの入手(https://www.post.japanpost.jp/zipcode/dl/readme.html)
- unzipでの解凍と、iconvでのUTF-8変換(KEN_ALL.UTF-8)
- 複数レコード分割の解消(38文字制限などの問題解消)
- 一つの郵便番号で二以上の町域を表す場合の分割
- 住所3等の「()」内表記や「以下に掲載がない場合」の削除
- 住所2等の「~郡~町」や「~郡~村」や「~市~区」の分割
- 登録語彙と読みの抽出と基本語彙に名詞(住所可)として登録(優先順位は最低に近い定数: 3)
- 郵便番号から住所への変換を合成語辞書登録(基本語彙の間接参照登録)
元ライセンス: 郵便番号データに限っては日本郵便株式会社は著作権を主張しません。自由に配布していただいて結構です。
KEN_ALL.ZIP (郵便番号データファイル)の形式等の仕様情報
全角となっている町域部分の文字数が38文字を越える場合、また半角となっているフリガナ部分の文字数が76文字を越える場合は、複数レコードに分割しています。
この郵便番号データファイルでは、以下の順に配列しています。
- 全国地方公共団体コード(JIS X0401、X0402)……… 半角数字
- (旧)郵便番号(5桁)……………………………………… 半角数字
- 郵便番号(7桁)……………………………………… 半角数字
- 都道府県名 ………… 半角カタカナ(コード順に掲載) (注1)
- 市区町村名 ………… 半角カタカナ(コード順に掲載) (注1)
- 町域名 ……………… 半角カタカナ(五十音順に掲載) (注1)
- 都道府県名 ………… 漢字(コード順に掲載) (注1,2)
- 市区町村名 ………… 漢字(コード順に掲載) (注1,2)
- 町域名 ……………… 漢字(五十音順に掲載) (注1,2)
- 一町域が二以上の郵便番号で表される場合の表示 (注3) (「1」は該当、「0」は該当せず)
- 小字毎に番地が起番されている町域の表示 (注4) (「1」は該当、「0」は該当せず)
- 丁目を有する町域の場合の表示 (「1」は該当、「0」は該当せず)
- 一つの郵便番号で二以上の町域を表す場合の表示 (注5) (「1」は該当、「0」は該当せず)
- 更新の表示(注6)(「0」は変更なし、「1」は変更あり、「2」廃止(廃止データのみ使用))
- 変更理由 (「0」は変更なし、「1」市政・区政・町政・分区・政令指定都市施行、「2」住居表示の実施、「3」区画整理、「4」郵便区調整等、「5」訂正、「6」廃止(廃止データのみ使用))
※1 文字コードには、MS漢字コード(SHIFT JIS)を使用しています。 ※2 文字セットとして、JIS X0208-1983を使用し、規定されていない文字はひらがなで表記しています。 ※3 「一町域が二以上の郵便番号で表される場合の表示」とは、町域のみでは郵便番号が特定できず、丁目、番地、小字などにより番号が異なる町域のことです。 ※4 「小字毎に番地が起番されている町域の表示」とは、郵便番号を設定した町域(大字)が複数の小字を有しており、各小字毎に番地が起番されているため、町域(郵便番号)と番地だけでは住所が特定できない町域のことです。
<小字に同一番地が存在する住所> ○○市△△町が郵便番号の表す範囲であり、町域(郵便番号)と番地だけでは住所が特定できません。
○○市△△町字A100番地
○○市△△町字B100番地
○○市△△町字C100番地
※5 「一つの郵便番号で二以上の町域を表す場合の表示」とは、一つの郵便番号で複数の町域をまとめて表しており、郵便番号と番地だけでは住所が特定できないことを示すものです。 ※6 「変更あり」とは追加および修正により更新されたデータを示すものです。 ※7 全角となっている町域名の文字数が38文字を超える場合、また、半角カタカナとなっている町域名のフリガナが76文字を越える場合には、複数レコードに分割しています。
データの格納イメージ
各項目は、半角の「,」(カンマ)で区切っており、上記の2)~9)までの項目は「"」(ダブルクォーテーション)で囲んでいます。 上記4)~9)までは可変長形式であり、空白のない形式です。 1レコードの区切りは、キャリッジリターン(CR)+ラインフィード(LF)です。 9)の項目位置に、「“以下に掲載がない場合”」とは、お探しの町域が見つからない場合にお書きいただく番号であり、町域を特定するものではありませんのでご注意ください。 9)の項目位置に、「"○○市(または町・村)の次に番地がくる場合"」とは、市区町村名の後ろに町域名がなく、番地がくる住所(例:○○郡△△町1234番地)の場合にお書きいただく番号です。 9)の項目位置に、「"○○市(または町・村)一円"」とは、町域名がない市区町村の場合にお書きいただく番号です。
固有名詞(駅名)辞書補強: 日本全国駅名一覧
処理手続き案
- 全国駅名一覧ファイル(sta_list.lzh)をダウンロードする(171KB)http://www5a.biglobe.ne.jp/~harako/data/station.htm
- lhaでの解凍と、iconvでのUTF-8変換(sta_list.UTF-8)
- 駅名と読みの抽出と基本語彙に名詞(駅名可)として登録(優先順位は最低に近い定数: 3)
- 鉄道路線名の抽出とふりがな付与(mecab+unidic)
- 鉄道路線名の合成語辞書登録(基本語彙の間接参照登録)
元ライセンス: 利潤の追求などは全く考慮に入れていません。従いまして、このデータを利用されるのは自由ですが、その際に不利益を被ったりした場合でも、スナフキんは一切責任は負えませんことをご承知おき下さい(もっとも、利用の方法はほとんどないとは思いますが。ただの羅列ですから…)。また、内容に関しましても、気がついたエラーはその都度直していますが、人間の手入力が基礎になっていますから、入力ミスがないとも限りません。ご注意願います(お気づきのエラーがありましたら、是非指摘していただけると幸いです)。
名前の参考情報
まず、ざっくりとした現状を見る。
男の子の人気名前ランキング 等を参考に、短単位語彙表でのランクなどと並べると以下となる。
RANK PMW
#1 ヒロト #31106 0.89
#10 ハヤト #18828 2.06
#100 コウダイ #100044 0.05
OLD #1 ヒロシ #2878 29 (昔最も多かったという名前)
公開サイトでさらに状況を見ると:
- https://oterac.com/yom/ (一番使いやすい、HITが少なそう、ひろし=50)
- http://name.m3q.jp/list?g=&s=%E3%81%B2%E3%82%8D%E3%81%97 list?g=&s=ひろし (使いやすい、ひろし=121)
- https://namehintbox.com/yomitokanji.php?yomi=%E3%81%B2%E3%82%8D%E3%81%97 yomi=ひろし (ひろし=70?)
- https://mnamae.jp/p/30d230ed30b7_1.html (ひろし=100?)
- https://mamasup.me/articles/70595 (ひろし=195)UnihanデータベースのSQLでの利用
- https://kanjitisiki.com/namae2/otoko/27/hirosi.html
- http://kanji-database.sourceforge.net/software/database.html LICENSE basically distributed under GPL License.
こうみると、「ひろし」にはかなりの漢字表現がある。
ちなみに、表記法が多いサイトは、ありえない表記も記載している感もなきにしもあらずである。
anthyが候補として示す82の候補程度がいい線の感がある。
名字・名前の公開サイト
以下は面白い情報源だが、特に使う必要は無い。ライセンス問題に悩むこともない。
少なくとも、公開サイトで検索用に提供している場合、 人力検索で見て共通漢字表現を探し、
読んだデーターを人間が咀嚼し利用する程度ならFAIR USEでしょう。ただ面倒な事が書いてあ
ることがあるのも現実です。
ちょっとデーター作成に直接使うのはライセンスコンタミが心配。ただ比較参照には便利そう。
- 全国名字ランキング https://myoji-yurai.net/prefectureRanking.htm?prefecture=%E5%85%A8%E5%9B%BD&page=0
- 特徴:ここは、名前の読みも調べられる。
- 利用条件 ※ランキングや人数、読み、解説などの名字データをご利用される場合は、 「参考資料 名字由来net」「名字由来netより引用」「出典 名字由来net」などと記載、 そしてURLへリンクしていただき、自由にご活用ください。
この程度は他リソースにもほぼ同じ情報有り。
-
同姓同名辞典 http://www.douseidoumei.net/00/sei40.html
- 利用条件 こちらは、自分の名前を探す同姓同名検索や都道府県別の苗字や名前のランキング調査、 珍しい苗字や名前の確認などにご利用ください。(網羅的に対応する上でライセンス的に利用しやすい)
-
日本人の名字ランキング http://home.r01.itscom.net/morioka/myoji/best200.html
- 利用条件 無断での複製・転用などは固くお断りします。
四文字熟語、三文字熟語の補強策
少々本題から外れるが備忘録:
長単位語彙表
ほきょうさく 補強策 (#405809 頻度0.03pmw)
短単位語彙表
ほきょう 補強 ー 確定
さく 策 ー 他候補有り
ー>連語登録などの方策が必要か?
| Previous Post | Top | Next Post |